


|
IT Security Professional
|


4 public comments




Had a situation this week where I googled an error message... only to find the GitHub issue I raised about that exact error message 5 years ago.
New York, NY







We should train search engines and AI with this logic so they stop giving the 10-year-old response with 40 replies over the current response with only 2 replies.

Please, we need your help. Our research suggests you're the last living descendant of the person who knew how to format this config file.

You’re not outsourcing work to AI. You’re creating organizational sludge slowing down your experts.
I have over 20 years of experience in running infrastructure. I’m what many people would call an “expert” in my field. I’m spending most of my time reviewing other people’s low effort output.
I’m not saying LLM output can’t be useful. Use the word prediction machine to help you predict better words. Don’t foist the words on other people without critically thinking about what you created.
You are still responsible for the quality of your output. There used to be a cultural standard: if I created crap, my work was crap. This was eventually enforced by leadership through employee reviews and project assignments.
Now the culture has shifted to only reward output velocity and the experts are demoted to expertise spell checkers. The value I’m allowed to bring is friction to the slop factory. This is primarily driven by leadership who are the most prolific slingers of slop. It’s no wonder they want to fire so many people.
Your experts are drowning. They can’t do the quality work you hired them to do because all the slop flows towards the well of knowledge. The sludge is clogging the gears of organizational process and leadership views it as a new coat of paint.
We already see the sludge affecting traditional software development lifecycles. PR reviews are the new bottleneck, assuming someone cares. Git is too cumbersome. Feedback loops aren’t fast enough. Maybe we should just vibe in prod.
Artists are even worse. AI “designs” require more fixing than code. LLMs don’t have taste and design doesn’t have a linter. Humans you hired are cleaning up the crap.
Marketing is in the same boat. No one cares if the content is true. Just create more of it. The attention economy is being consumed by the snake eating its own tail.
Anyone on the receiving end of the slop knows this isn’t sustainable. Anyone on the sending end of the slop doesn’t see the exponential effects. Expertise requires experience and applying that expertise is slow and thoughtful. The pace of output doesn’t allow for it.
You can’t put the slop back in the bottle, but you need to distribute the sludge to thin it out.


Steve Yegge’s article about programmer burnout (“The AI Vampire”) along with Margaret Storey’s article about Cognitive Debt started an ongoing conversation about programmer fatigue and software quality—two topics that should be linked, but often aren’t. Steve argues that programming constantly with the help of agentic AI leds to burnout; it’s fast, it’s fun, but keeping up with your agents causes mental strain. He recommends programming with agents no more than 4 or 5 hours per day. I could cynically say that most software developers spend at most 20% of their time writing code, which leaves about an hour and a half for wrestling with agents—but that’s beside the point. Yegge’s point about burnout is important, and is in line with what friends have told me. At some point, you have to put the laptop down.
Storey makes a different point. Agentic engineering is great at creating software that works, but that you don’t quite understand. Like humans, agents can generate a lot of spaghetti code. They can “design” convoluted and inappropriate software structures—I hesitate to call them “architectures”; they’re what happens in the absence of architecture. Agents are very capable of creating technical debt—and not the kind of meaningful technical debt that lets you release a product on time with the knowledge that you need to make pay it back with interest. If nobody is looking hard at the code, the debt can grow without bounds, sort of like not checking your credit card balance. What’s worse—and this is Storey’s contribution—while that technical debt is growing, developers are losing track of the design, the structure, the architecture. She calls that “cognitive debt.” You don’t just have problems in the code; those problems are harder to find and fix than they should be because you’re unclear on the structure of the code you’re working with.
Other voices have made similar points. The Sonarsource blog writes about how AI is reshaping technical debt and creating new burdens, new kinds of toil. In “The Mythical Agent Month,” Wes McKinney links the problem of burnout to the introduction of “accidental complexity” and “agent scope creep,” while Tim O’Brien writes that while scope creep isn’t new, AI supersized its growth. And Addy Osmani writes about finding your parallel agent limit, coming to grips with what you’re capable of accomplishing without compromising your work or your life.
Cognitive debt and burnout aren’t new, alas. With or without AI, we’ve all stayed up to 4AM working on a bug that won’t go away or pursuing an interesting idea to its end. Sometimes that’s heroic, but AI threatens to turn it into a lifestyle. AI fatigue is real, as Siddhant Khare writes, and it’s something we need to talk about. When fatigued, it’s tempting to say “this works, it looks good, and it passes our tests” without considering how the code fits into the overall plan. With 10x code generation, you also get 10x the debt load, and that’s being optimistic. When the debt curve goes exponential, strategies for managing that debt are stressed past the breaking point.
The problem with cognitive debt is that it eventually makes new features and bug fixes difficult or impossible. The code has become so convoluted that it can’t be changed. I’ve certainly done that with hand-written code: added a feature without thinking enough about how the new code fit in, added some more code later, and then—when I needed to add a third feature—discovered that I’d created a problem that wouldn’t be simple to fix. The right stuff was there, but in the wrong places because I wasn’t thinking about the overall structure.
That’s a common enough problem with handwritten code; it’s almost always a problem with legacy code where the original developers and maintainers are no longer around. We need to realize that it’s also a problem with AI-generated code, which has been characterized as legacy code from the day it’s written. Somebody or something has to pay down the debt. As Storey writes, “velocity without understanding is not sustainable”: not for humans, not for machines. If you understand the structure of what you’re building, you can steer the AI away from creating a problem in the first place, or you can use it to author a fix. If you don’t understand the structure or can’t describe it to the AI, you’re lost.
Cognitive debt accumulates much more quickly when you’re burned out. Burnout has always been a problem for programmers, especially for those who really love programming: you stay up all night to solve a problem. And, while some programmers resist using AI to write code, those who use AI frequently find that it exacts the same toll: it’s hard to stop. It is its own kind of toil: toil that gives you a sense of accomplishment and fulfillment, but still leaves you empty.
Agents may not be subject to burnout, but the humans who control them are. Agents are quickly becoming more capable, but they still can’t maintain a sense of the shape and structure of a project over the long term. That’s our job. They can pay down technical debt, but only if properly guided; that’s also our job. And we won’t be able to do either if we’re burned out.

Supporting a large codebase is challenging. Sometimes, the questions you have can’t be answered by the code at hand. For example, “When did we switch from class components to hooks and what discussion led to that decision?” or “Did we used to have logging here for invalid keys?” or “Did we ever have code to handle Zstd compression?”
Git’s search is challenging for these sorts of queries. git log --grep="auth" assumes you remember exact words from commit messages. Want to find “commits where we improved error handling in API endpoints”? You’ll need multiple greps with regex gymnastics, and still miss commits that used different terminology. We need a better tool.
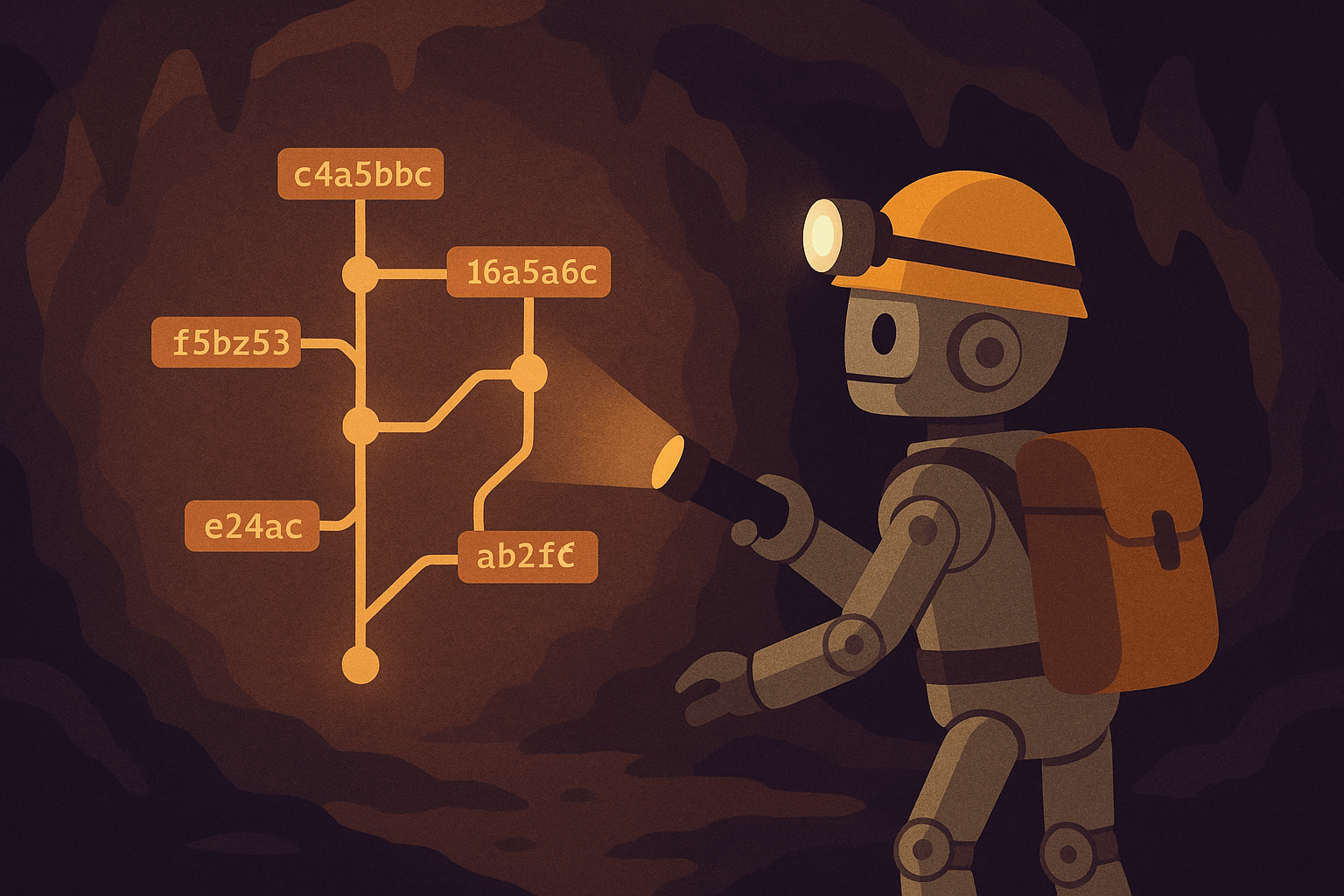
Enter Spelungit
I built Spelungit, a semantic search engine for Git commit history. Instead of keyword roulette, you search using natural language through Claude Code’s MCP interface.
Want commits where you refactored authentication? Ask for “authentication flow refactoring.” Looking for race conditions in background processing? Search for “race conditions in job processing.” It understands intent instead of making you guess exact words from three months ago.
How it works
Instead of this:
# How do you even grep for "race condition fixes"?
git log --grep="race\|concurrent\|thread\|lock\|mutex" --all
# Now manually read through 50 commits...
You do this in your AI development tool of choice:
Search git history for "race condition fixes in background jobs"
Queries that work:
- “When did we switch from REST to GraphQL?”
- “Commits where we improved error handling in API endpoints”
- “Show me refactoring of the authentication flow”
- “Security improvements in file upload handling”
- “Where did we fix that memory leak in the worker process?”
It creates embeddings for both commit messages and code changes, which makes semantic search possible. It knows the difference between new features and bug fixes, even when commit messages are vague (looking at you, past me).
Installation
Spelungit uses SQLite and local embeddings to make installation simple. Everything runs on your machine. No need for an API key, a database, or Docker.
One line:
curl -sSL https://raw.githubusercontent.com/haacked/spelungit/main/install-remote.sh | bash
Downloads everything, sets up Python venv, installs dependencies, configures Claude Code. Suspicious of pipe-to-bash? Clone the repo and run ./install.sh.
Using it
Shows up in Claude Code (or your AI tool of choice) as an MCP server. The first time you ask a question in a repository that spelungit responds to, spelungit will index the repository. Once it’s done, it’ll be able to answer questions.For large repos, this can take a few minutes while it analyzes commits and creates embeddings.
Then search naturally:
- “Show me commits about error handling improvements”
- “Find where we refactored the authentication”
- “What changed in the API layer recently?”
Claude calls the appropriate MCP tools (index_repository, search_commits, repository_status, get_database_info) behind the scenes.
Under the hood
Analyzes commit messages and code changes. For each commit:
- Semantic content from messages and diffs
- Code patterns like function names and classes
- File types and directory structure
- Feature vs. bug fix vs. refactoring
Uses Microsoft’s all-MiniLM-L6-v2 (384 dimensions) with local sentence-transformers to create embeddings. Embeddings are stored in SQLite. Searching for git history uses cosine similarity searches.
The sqlite database only stores commit SHAs and embeddings, leaving the full commit message in git. Thousands of commits = few megabytes. Handles Git worktrees if you’re into that masochism.
Why I built this
I work across multiple repositories and constantly need to understand why changes were made. Traditional Git tools are limited. Too much detective work scrolling through commits.
I wanted to ask Git history questions in plain English and get the right commits back. Semantic search of Git history is something I always wished GitHub would add. I got tired of waiting so I built this.
Also, I’ve been experimenting with MCP servers and wanted to build something useful instead of another todo app.
Future ideas for improvement
Configurable models: Local embeddings work pretty well, but OpenAI’s models would be better for teams willing to trade privacy for better accuracy. PostgreSQL support: For massive repos or shared team search. Smarter code understanding: Better refactoring vs. feature detection, architectural changes over time.
Try it
Spelungit is MIT licensed. The project scratched a real itch for me. If it doesn’t work perfectly, that’s what GitHub issues are for.
Find it at https://github.com/haacked/spelungit.
Denver, CO, USA





1 public comment


It's important for devices to have internet connectivity so the manufacturer can patch remote exploits.
Few musicians in the world of progressive rock and beyond have had as profound an impact on keyboard performance as Jordan Rudess. Known for his boundless creativity, jaw-dropping technical prowess, and insatiable thirst for innovation, Rudess has cemented his place as one of the greats of progressive keyboard playing. Whether stunning audiences as a core member of Dream Theater, collaborating with legendary artists, or pushing the boundaries of musical expression through cutting-edge technology, Rudess continues to redefine what it means to be a modern keyboardist.
Watch as Rudess gives a breathtaking performance at NAMM 2025, where he brings the future of keyboard artistry to life with ROLI Piano and Airwave.
A classically trained prodigy, Rudess was recognized early for his extraordinary talents, earning a place at the Juilliard School’s Pre-College division. While his foundation in classical music is undeniable, his passion for sonic exploration led him to progressive rock, fusion, and electronic music. His rise to fame began in earnest when he joined Dream Theater in 1999, a move that solidified his reputation as a transformative force in progressive metal. Beyond Dream Theater, Rudess has built an impressive solo career, crafting albums that explore a wide array of musical landscapes, and collaborations with the likes of Liquid Tension Experiment, Steven Wilson, and Tony Levin. But what truly sets him apart is his unwavering commitment to the future of music technology.
A pioneer in keyboard innovation using sampling and synthesizers, Rudess has been at the forefront of integrating groundbreaking instruments into his performances. His fascination with expressive digital instruments and his mastery of their ability to convey microtonal bends, fluid pitch transitions, and multi-dimensional expressiveness, showcases a new era of keyboard performance, one that bridges the gap between the traditional and the futuristic.
Demonstrating not only his staggering technique but also his visionary approach to sound design and musical storytelling, Rudess continues to inspire musicians and fans alike. By embracing new technologies while maintaining his deep-rooted musicality, he proves that the evolution of musical creativity has no limits.
These are some very cool new toys from Roli and Jordan Rudess is always fun to watch.
Denver, CO, USA
Next Page of Stories